Study design
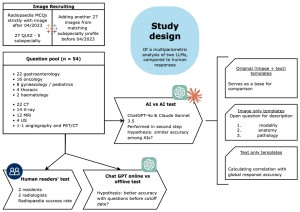
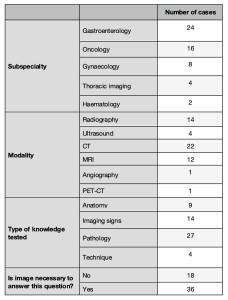
A total of 54 multiple choice questions (QCM) of the “single select” type was retrieved from Radiopaedia.org’s quiz section, with permission from the Editor. The dataset was composed of an equal number of questions published before April 2023, and from then on (2x27 questions; the cutoff coincident with the end of GPT’s training phase). The questions were chosen across different subspecialties including gastroenterology, oncology, and gynaecology/paediatrics. Each question provided clinical context and 4-5 response options
Four readers answered the questions: two junior residents and two board-certified radiologists. Readers were blinded to the others’ answers and responded independently within a 90-second time limit per question, without access to external resources.
The two LLM with image processing capabilities that were tested:GPT-4o (OpenAI, San Francisco, CA, USA) with and without internet access in June 2024, and with internet access in September 2024Claude 3.5 Sonnet (Anthropic, San Francisco, CA, USA), an LLM that inherently does not have internet access, in September 2024
LLM test protocol:1. Initial assessment (July 2024): Performance evaluation of GPT-4o online and offline versions' performance on pre-April 2023 Radiopaedia questions and questions posted thereafter, to assess the influence training data might have had in the training phase of the model. An identical template was used for prompting for all 54 questions requesting answer whilst transmitting the text and relevant image.2. Comprehensive assessment (September 2024) AI vs. AI: Compared the then updated GPT-4o LLM with Claude 3.5 Sonnet in performing on the same list of quiz questions. In this second phase we developed two templates with additional questions, to gain further insight on the mechanisms of AI’s decision-making In addition to resubmitting the original template, we added (1) a template for the isolated imaged analysis, asking the machine to name the modality, anatomical structures and pathology on the image; (2) a template submitting the question text only, asking for an answer based only on the MCQ text partAll AI evaluations were performed with zero-shot prompting, implying the opening of a new chat session per question, to minimize memory retention bias.
Statistical analyses:ANOVA was used to search for significant differences between answers to the same question when using the three templates (text+image, image-only, text-only).Chi-squared test was applied determining if there was a significant association between variables, using contingency tables.